默认情况下,每个Flink集群只有一个JobManager,这将导致单点故障(SPOF,single point of failure),如果这个JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败,这是我们可以对JobManager做高可用(High Availability,简称HA),JobManager HA集群当Active JobManager节点挂掉后可以切换其他Standby JobManager成为主节点,从而避免单点故障。用户可以在Standalone、Flink on Yarn、Flink on K8s集群模式下配置Flink集群HA,Flink on K8s集群模式下的HA将单独在K8s里介绍。
Standalone模式下,JobManager的高可用性的基本思想是,任何时候都有一个Alive JobManager和多个Standby JobManager。Standby JobManager可以在Alive JobManager挂掉的情况下接管集群成为Alive JobManager,这样避免了单点故障,一旦某一个Standby JobManager接管集群,程序就可以继续运行。Standby JobManagers和Alive JobManager实例之间没有明确区别,每个JobManager都可以成为Alive或Standby。
Standalone集群部署下实现JobManager HA 需要依赖ZooKeeper和HDFS,Zookeeper负责协调JobManger失败后的自动切换,HDFS中存储每个Flink任务的执行流程数据,因此要有一个ZooKeeper集群和Hadoop集群。这里我们选择3台节点作为Flink的JobManger,如下:
 (资料图片)
(资料图片)
节点IP | 节点名称 | JobManager | TaskManager |
|---|---|---|---|
192.168.179.4 | node1 | ★ | ★ |
192.168.179.5 | node2 | ★ | ★ |
192.168.179.6 | node3 | ★ | ★ |
以上node1、node2、node3都是JobManager,同时只能有1个JobManager为Active主节点,其他为StandBy备用节点,配置JobManager HA 步骤如下:
所有Flink节点配置hadoop classpath由于Flink JobManager HA 中需要连接HDFS存储job数据,所以Flink所有节点必须配置hadoop classpath 环境变量,在node1-3所有节点上配置/etc/profile配置环境变量:
#配置/etc/profileexport HADOOP_CLASSPATH=`hadoop classpath`#执行生效source /etc/profile需要在所有Flink集群节点上配置$FLINK_HOME/conf/master文件,配置上所有的JobManager节点信息:
#node1,node2,node3节点上配置$FLINK_HOME/conf/master文件node1:8081node2:8081node3:8081需要在所有Flink集群节点上配置$FLINK_HOME/conf/flink-conf.yaml文件,这里在node1-3节点上配置,配置内容如下:
#要启用高可用,选主协调者为zookeeper,zk存储一些ck记录及选举信息high-availability: zookeeper#storageDir存储恢复JobManager失败所需的所有元数据,如:job dataflow信息high-availability.storageDir: hdfs://mycluster/flink-standalone-ha/#分布式协调器zookeeper集群high-availability.zookeeper.quorum: node3:2181,node4:2181,node5:2181#根ZooKeeper节点,所有集群节点都位于根节点之下。high-availability.zookeeper.path.root: /flink-standalone-ha#给当前集群指定cluster-id,集群所有需要的协调数据都放在该节点下。high-availability.cluster-id: /standalone-clusterStandalone HA 配置完成后,按照如下步骤进行测试:
启动Zookeeper,启动HDFS#在 node3、node4、node5节点启动zookeeper[root@node3 ~]# zkServer.sh start[root@node4 ~]# zkServer.sh start[root@node5 ~]# zkServer.sh start#在node1启动HDFS集群[root@node1 ~]# start-all.sh#在node1 节点启动Flink Standalone HA集群[root@node1 ~]# cd /software/flink-1.16.0/bin/[root@node1 bin]# ./start-cluster.shStarting HA cluster with 3 masters.Starting standalonesession daemon on host node1.Starting standalonesession daemon on host node2.Starting standalonesession daemon on host node3.Starting taskexecutor daemon on host node1.Starting taskexecutor daemon on host node2.Starting taskexecutor daemon on host node3.启动Standaloe集群时同时会在node2、node3节点上启动JobManager。
访问Flink WebUI登录Flink WebUI (https://node1:8081/https://node2:8081/https://node3:8081),无论登录node1,node2,node3节点任意一台节点的WebUI 页面都相同:
在WebUI中无法看到哪个节点是Active JobManager,我们也可以通过zookeeper查看当前Active JobManager节点,命令如下:
#登录zookeeper 客户端[root@node5 ~]# zkCli.sh#查看对应节点路径信息[zk: localhost:2181(CONNECTED) 1] get /flink-standalone-ha/standalone-cluster/leader/dispatcher/connection_info ...w42akka.tcp://flink@node1:33274/user/rpc/dispatcher_1srjava.util.UUID...我们可以在Flink Standalone集群中提交一个Flink 任务,提交之后无论在通过哪个节点的8081WebUI都可以看到此任务。提交任务命令如下:
#在node5节点启动 socket服务[root@node5 ~]# nc -lk 9999#在node4客户端向Standalone集群提交任务[root@node4 ~]# cd /software/flink-1.16.0/bin[root@node4 bin]# ./flink run -m node1:8081 -d -c com.mashibing.flinkjava.code.chapter3.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar通过https://node1:8081、https://node2:8081、https://node3:8081 WebUI都可以看到提交的任务信息:
在HDFS中也可以看到提交的任务信息:
将node1节点上的JobManager进程kill掉,查看Active JobManager是否变化:
#kill node1 JobManager进程[root@node1 bin]# jps...16309 StandaloneSessionClusterEntrypoint...[root@node1 bin]# kill -9 16309将Active JobManager kill之后访问各个节点的WebUI可以看到短暂的不可用,稍等一会就可以看到正常可以访问除node1之外的其他节点WebUI,通过查询Zookeeper中节点信息,可以看到Active JobManager 节点切换成了其他节点:
#zookeeper查询命令[zk: localhost:2181(CONNECTED) 1] get /flink-standalone-ha/standalone-cluster/leader/dispatcher/connection_info...w42akka.tcp://flink@node2:35581/user/rpc/dispatcher_1srjava.util.UUID...通过以上测试Flink Standalone HA 生效,如果想要把在node1上kill掉的JobManager启动起来,需要手动执行如下命令:
#在node1启动JobManager[root@node1 bin]# ./jobmanager.sh start被kill的JobManager重新启动后作为备用的JobManager也可以访问WebUI查看集群中执行的任务。
正常基于Yarn提交Flink程序,无论使用哪种模式提交任务都会启动JobManager角色,JobManager角色是哪个进程可以通过Yarn WebUI查看对应的ApplicationID启动所在节点的对应进程, Yarn Session提交任务模式中该角色进程为"YarnSessionClusterEntrypoint"、Yarn Per-Job提交任务模式中该角色进程为"YarnJobClusterEntrypoint"、Yarn Application提交任务模式中该角色进程为"YarnApplicationClusterEntryPoint"。
当JobManager进程挂掉后,也就是Yarn Application任务失败后默认不会进行任务重试,所以Flink 基于Yarn JobManager HA的本质是当Yarn Application程序失败后重试启动JobManager,实际上就是通过配置Yarn重试次数来实现高可用。JobManager重试过程需要借助zookeeper 协调JobManger失败后的切换,进而进行恢复对应的任务,同时需要HDFS存储每个Flink任务的执行流程数据。
Yarn HA配置步骤如下:
修Hadoop中所有节点的yarn-site.xml在所有Hadoop节点上配置$HADOOP_HOME/etc/hadoop/yarn-site.xml文件,配置应用程序失败后最大尝试次数,以下该参数默认值为2,不配置也可以:
#设置提交应用程序的最大尝试次数,建议不低于4,这里重试的是ApplicationMaster yarn.resourcemanager.am.max-attempts 4 只需要在向Yarn提交任务的客户端节点上配置Flink的flink-conf.yaml文件。未来我们在node5节点上来基于Yarn 各种模式提交任务,所以这里我们在node5节点上配置$FLINK_HOME/conf/flink-conf.yaml文件,配置内容如下:
#要启用高可用,选主协调者为zookeeper,zk存储一些ck记录及选举信息high-availability: zookeeper#storageDir存储恢复JobManager失败所需的所有元数据,如:job dataflow信息high-availability.storageDir: hdfs://mycluster/flink-yarn-ha/#分布式协调器zookeeper集群high-availability.zookeeper.quorum: node3:2181,node4:2181,node5:2181#根ZooKeeper节点,所有集群节点都位于根节点之下。high-availability.zookeeper.path.root: /flink-yarn-ha#给当前集群指定cluster-id,集群所有需要的协调数据都放在该节点下。high-availability.cluster-id: /yarn-cluster#该参数同yarn-site.xml中yarn.resourcemanager.am.max-attempts参数,指向yarn提交一个application重试的次数,也可以不设置,非高可用默认为1,高可用默认为2,建议不大于yarn.resourcemanager.am.max-attempts参数,否则会被yarn.resourcemanager.am.max-attempts替换掉。yarn.application-attempts: 4#在 node3、node4、node5节点启动zookeeper[root@node3 ~]# zkServer.sh start[root@node4 ~]# zkServer.sh start[root@node5 ~]# zkServer.sh start#在node1启动HDFS集群[root@node1 ~]# start-all.sh这里以在node5节点上以Yarn Application模式提交任务为例,命令如下:
#在node5节点启动 socket服务[root@node5 ~]# nc -lk 9999#以Application模式提交任务,命令如下[root@node5 ~]# cd /software/flink-1.16.0/bin/[root@node5 bin]# ./flink run-application -t yarn-application -c com.mashibing.flinkjava.code.chapter3.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar以上任务提交后可以在Yarn WebUI中看到对应的Application信息:
测试Flink Yarn HA在Yarn WebUI中进入到FlinkWebUi页面,查看该JobManager启动所在的节点:
进入JobManager所在节点,并kill对应的JobManager进程,模拟JobManager进程意外中断,在Yarn WebUI中可以看到对应的Yarn ApplicationID重试执行,点击该ApplicatID 可以看到该任务重试信息:
通过以上测试,Flink Yarn HA 生效。




 中国无人驾驶技术初创公司文远知行考虑IPO 最早于今年上市
中国无人驾驶技术初创公司文远知行考虑IPO 最早于今年上市
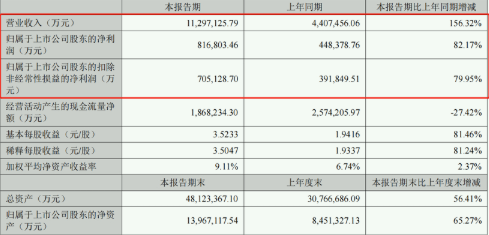 宁德时代上半年营业收入同比增156.32% 研发投入逼近同期净利
宁德时代上半年营业收入同比增156.32% 研发投入逼近同期净利
 兰博基尼上半年业绩创纪录 上半年生产5090辆汽车
兰博基尼上半年业绩创纪录 上半年生产5090辆汽车
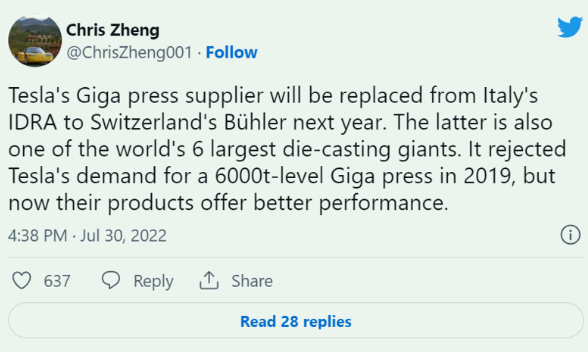 传特斯拉或引入另一家压铸机供应商 不会取消与IDRA合作
传特斯拉或引入另一家压铸机供应商 不会取消与IDRA合作
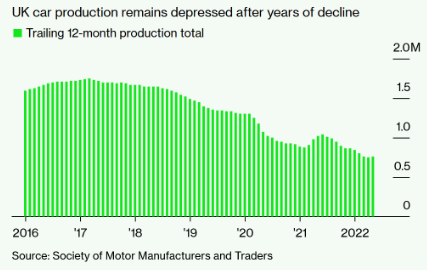 高油价有助于加速向电动汽车转型 英国5月汽车产量同比增13%
高油价有助于加速向电动汽车转型 英国5月汽车产量同比增13%