树是一种非顺序数据结构,它用于存储需要快速查找的数据。现实生活中也有许多用到树的例子,比如:家谱、公司的组织架构图等。
 (资料图片)
(资料图片)
本文将详解二叉搜索树并用TypeScript将其实现,欢迎各位感兴趣的开发者阅读本文。
实现思路
二叉树中的节点最多只能有两个子节点:一个是左侧子节点,另一个是右侧子节点。
二叉搜索树是二叉树的一种,它与二叉树的不同之处:
每个节点的左子节点一定比自身小
每个节点的右子节点一定比自身大
本文主要讲解树的具体实现,不了解树基础知识的开发者请移步:数据结构:二叉查找树
二叉搜索树的实现
根据二叉搜索树的特点我们可知:每个节点都有2个子节点,左子节点一定小于父节点,右子节点一定大于父节点。
创建辅助类Node
首先,我们需要一个类来描述二叉树中的每个节点。由二叉树的特点可知,我们创建的类必须包含如下属性:
key节点值
left左子节点的引用
right右子节点的引用
和链表一样,我们将通过指针来表示节点之间的关系,在双向链表中每个节点包含两个指针,一个指向下一个节点,两一个指向上一个节点。树也采用同样的方式(使用两个指针),但是树的指针一个指向左子节点,另一个指向右子节点。
下图描述了一个二叉树,节点与节点之间的链接就是指针。
创建二叉搜索树的基本结构
我们采用与链表相同的做法,通过声明一个变量来控制此数据结构的第一个节点(根节点),在树中此节点为root。
接下来,我们来分析下实现一个二叉搜索树都需要实现的方法:
insert(key):向树中插入一个节点
search(key):在树中查找一个键。如果节点存在返回true,否则返回false
min:返回树中最小的值/键
max:返回书中最大的值/键
remove(key):从树中移除某个键
向树中插入一个新的节点
验证插入操作是否为特殊情况:根节点为null,如果根节点为null则创建一个Node类的实例并将其赋值给root属性,将root指向新创建的节点
如果根节点不为null,则需要寻找合适的位置来插入子节点,因此我们需要实现一个辅助方法insertNode
insertNode方法接收两个参数:要从哪里开始插,要插入节点的key
由于二叉搜索树有一个特点是:左子节点小于父节点,右字节点大于父节点。所以我们需要创建一个比对方法compareFn
compareFn方法接收两个参数:要比对的值,原值。如果小于则返回-1,如果大于则返回1,相等则返回0
调用compareFn方法判断要插入的键是否小于当前节点的键
如果小于,判断当前节点的左子节点是否为null,如果为null则创建Node节点将其指向左子节点,否则从当前节点的左子节点位置开始递归调用insertNode方法,寻找合适的位置
如果大于,判断当前节点的右子节点是否为null,如果为null则创建Node节点将其指向右子节点,否则从当前节点的右子节点位置开始递归调用insertNode方法,寻找合适的位置
接下来,我们通过一个例子来描述下上述过程。
我们要将下述数据插入二叉树中:3021251817353331
首先,插入30,此时根节点为null,创建一个Node节点将其指向root
然后,插入21,此时比较21和30的大小,21<30。在30的左子节点插入,30的左子节点为null。因此直接插入
然后,插入25<30,在30的左子节点插入,此时30的左子节点已经有了21,递归调用insertNode,比较25和21的大小,25>21,因此在21的右子节点插入
依此类推,直至所有节点都插入。
搜索树中的值
在树中,有三种经常执行的搜索类型:
搜索最小值
上个例子,我们将所有的节点插入到二叉树后,我们发现树最左侧的节点是这颗树中最小的键
因此我们只需要从根节点一直沿着它的左子树往下找就可以找到最小节点了
搜索最大值
树最右侧的节点是这颗树中最大的键
因此我们只需要从根节点一直沿着它的右子树往下找就可以找到最大节点了
搜索特定的值
首先声明一个方法search,search方法接收一个参数:要查找的键,它需要一个辅助方法searchNode
searchNode接收两个参数:要查找的节点,要查找的键,它可以用来查找一棵树或其任意子树的一个特定的值
首先需要验证参数传入的节点是否合法(不是null或undefined),如果是说明要找的键没找到,返回false
调用compareFn方法比对要查找节点与当前节点的key进行大小比较
如果要查找的节点小于当前节点的key,则递归调用searchNode方法,传当前节点的左子节点和要查找的key
如果要查找的节点大于当前节点的key,则递归调用searchNode方法,传当前节点的右子节点和要抄着的key
否则就是相等,则节点已找到,返回true
接下来,我们通过一个例子来描述下搜索特定的值的过程。
如下图所示为一个二叉搜索树,我们需要判断25是否在树中:
调用search方法,要查找的键为25,调用searchNode方法,需要从根节点开始找,因此传root和要查找的key
首先,node不为空,则继续判断key与根节点键的大小,25<30,递归它的左子树
然后,比较25和21的大小,25>21,递归它的右子树
此时,25===21,节点已找到,返回true
移除一个节点
移除树中的节点remove,它接收一个参数key,它需要一个辅助方法removeNode,它接收两个参数:节点,要移除的key。
removeNode实现思路如下:
首先,判断节点是否为null,如果是则证明节点不存在返回null
调用compareFn方法,比较要删除的key与当前节点key的大小
如果要删除的key小于当前节点key,则递归调用removeNode方法,传当前节点的左子节点和key
如果要删除的key大于当前节点key,则递归调用removeNode方法,传当前节点的右子节点和key
否则就是找到了要删除的节点,删除节点可能出现三种情况:
需要先找到它右边子树的最小节点
用右子树最小节点的键去更新当前节点的键
更新完成后,此时树中存在了多余的键,需要调用removeNode方法将其删除
向其父节点更新节点的引用
当前节点的左子节点和右子节点都为null,此时我们只需要将节点指向null来移除它
当前节点包含一个左子节点或者右子节点,如果左子节点为null,将当前节点指向当前节点的右子节点。如果右子节点为null,将当前节点指向当前节点的左子节点。
当前节点有两个子节点,需要执行4个步骤:
二叉搜索树的遍历
遍历一棵树是指访问树的每个节点并对它们进行某种操作的过程,访问树的所有节点有三种方式:
中序遍历
先序遍历
后序遍历
树的遍历采用递归的形式访问,对递归不了解的开发者请移步:递归的理解与实现
中序遍历
中序遍历是一种上行顺序访问树节点的遍历方式,即从小到大的顺序访问所有节点。中序遍历的一种应用场景就是对树进行排序操作,接下来我们来分析下中序遍历的实现:
声明inOrderTraverse方法接收一个回调函数作为参数,回调函数用来定义我们对遍历到的每个节点进行的操作,中序遍历采用递归实现,因此我们需要一个辅助方法inOrderTraverseNode
inOrderTraverseNode方法接收两个参数:节点,回调函数
递归的基线条件node==null
递归调用inOrderTraverseNode方法,传当前节点的左子节点和回调函数
调用回调函数
递归调用inOrderTraverseNode方法,传当前节点的右子节点和回调函数
接下来,我们通过一个例子来描述下中序遍历的过程
如上图所示,蓝色字标明了节点的访问顺序,橙色线条表示递归调用直至节点为null然后执行回调函数。具体的执行过程如下:
11=>7=>5=>3ode:3,left:undefinedcallback(node.key)3right:undefinedallback(node.key)5node:5,right:6left:undefinedcallback(node.key)6right:undefinedcallback(node.key)7node:7,right:9left:8left:undefinedcallback(node.key)8right:undefinedcallback(node.key)9right:10left:undefinedcallback(node.key)10right:undefinedallback(node.key)11node:11,right:15left:13left:12left:undefinedcallback(node.key)12right:undefinedcallback(node.key)13right:14left:undefinedcallback(node.key)14right:undefined.........right:25left:undefined25callback(node.key)
先序遍历
先序遍历是以优先于后代节点的顺序访问每个节点的。先序遍历的一种应用是打印一个结构化的文档,接下来我们分析下先序遍历的具体实现:
声明preOrderTraverse方法,接收的参数与中序遍历一样,它也需要一个辅助方法preOrderTraverseNode
preOrderTraverseNode方法接收的参数与中序遍历一样
递归的基线条件:node==null
调用回调函数
递归调用preOrderTraverseNode方法,传当前节点的左子节点和回调函数
递归调用preOrderTraverseNode方法,传当前节点的右子节点和回调函数
接下来,我们通过一个例子来描述下先序遍历的过程:
如上图所示,蓝色字标明了节点的访问顺序,橙色线表示递归调用直至节点为null然后执行回调函数。
具体的执行过程如下:
node:11callback(node.key)11node.left=7ode:7callback(node.key)7node.left=5ode:5callback(node.key)5ode.left=3node:3callback(node.key)3node.left=undefined,node.right=undefined=>node:5node:5node.right=6callback(node.key)6node:6node.left=undefined,node.right=undefined=>node:7node:7node.right=9callback(node.key)9.........callback(node.key)25
后序遍历
后序遍历则是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是计算一个目录及其子目录中所有文件所占空间的大小,接下来我们来分析下后序遍历的实现:
声明postOrderTraverse方法,接收的参数与中序遍历一致
声明postOrderTraverseNode方法,接收的参数与中序遍历一致
递归的基线条件为node==null
递归调用postOrderTraverseNode方法,传当前节点的左子节点和回调函数
递归调用postOrderTraverseNode方法,传当前节点的右子节点和回调函数
调用回调函数
接下来,我们通过一个例子来描述下后序遍历的执行过程。
如上图所示,蓝色字标示了节点的执行顺序,橙色线表示递归调用直至节点为null然后执行回调函数。
具体的执行过程如下:
11=>7=>5=>3node:3left:undefinedright:undefinedcallback(node.key)3node:5right:6ode:6left:undefinedright:undefinedcallback(node.key)6node:5callback(node.key)5node:7right:9node:9left:8node:8left:undefinedright:undefinedcallback(node.key)8node:9right:10node:10left:undefinedright:undefinedcallback(node.key)10node:9callback(node.key)9node:7callback(node.key)7......callback(node.key)11
实现代码
前面我们分析了二叉搜索树的实现思路,接下来我们就讲上述思路转换为代码。
创建辅助节点
创建Node.ts文件
创建Node类,根据节点的属性为类添加对应属性
exportclassNode
完整代码请移步:Node.ts
创建二叉树的基本结构
创建BinarySearchTree.ts文件
声明root节点和比对函数
protectedroot:Node
exporttypeICompareFunction
实现节点插入
insert(key:T){if(this.root==null){//如果根节点不存在则直接新建一个节点this.root=newNode(key);}else{//在根节点中找合适的位置插入子节点this.insertNode(this.root,key);}}protectedinsertNode(node:Node
获取节点的最大值、最小值以及特定节点




 中国无人驾驶技术初创公司文远知行考虑IPO 最早于今年上市
中国无人驾驶技术初创公司文远知行考虑IPO 最早于今年上市
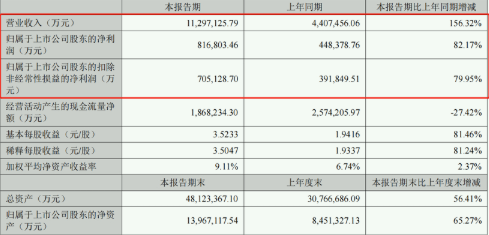 宁德时代上半年营业收入同比增156.32% 研发投入逼近同期净利
宁德时代上半年营业收入同比增156.32% 研发投入逼近同期净利
 兰博基尼上半年业绩创纪录 上半年生产5090辆汽车
兰博基尼上半年业绩创纪录 上半年生产5090辆汽车
 传特斯拉或引入另一家压铸机供应商 不会取消与IDRA合作
传特斯拉或引入另一家压铸机供应商 不会取消与IDRA合作
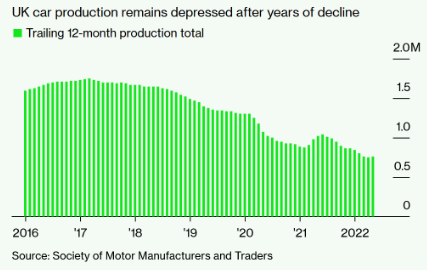 高油价有助于加速向电动汽车转型 英国5月汽车产量同比增13%
高油价有助于加速向电动汽车转型 英国5月汽车产量同比增13%